Hizkuntza bat ikasteko esperientziatik igarotzen den orok arreta berezia jarri behar izaten du hitzak nola konbinatzen diren jakiteko, maiz gramatikaren arauak ez baitira aski hiztunek hitzak nola erabiltzen dituzten aurresateko eta esplikatzeko.
Euskarazko urrats ingelesez step dela ikasita, eta eginerako do edo make erabil ditzakegula jakinda, modu naturalean sortuko ditugu to do steps edo to make steps konbinazioak gure urratsak egin adierazteko, harik eta norbaitek ezetz esan arte, horrela ez dela esaten, step hitzarekin take erabiltzen dutela ingelesdun “jatorrek”.

Ardoaz mintzatuz, euskaraz beltz dena gorri da beste zenbait hizkuntzatan (vin rouge, red wine, vino rosso, Rotwein…). Horrelakoak baino ezagunagoak dira, beharbada, adarra jo edo hautsak harrotu modukoak; horien adiera aurrez jakin ezean, nekez asmatuko dugu zer esan nahi duten osagaien esanahietatik abiatuta.

Lehenei kolokazio esan ohi zaie, eta bigarrenei lokuzio edo esapide idiomatiko, baina, diren motakoak direla, garrantzi handikoak dira, hizkuntzaren irakaskuntzan eta hiztegigintzan ez ezik, Hizkuntzaren Prozesamenduaren hainbat atazatan ere, hala nola itzulpen automatikoan eta terminologia-erauzketan. Esaterako, es → eu itzulpen automatikoko sistema batek ez badaki prestar atención konbinazio berezia dela, “arreta utzi” itzul lezake, hitzez hitz, arreta jarri itzuli beharrean.
Idiomatikotasunaren karakterizazio automatikoa
Kolokazioak eta lokuzioak hitz anitzeko unitate edo unitate fraseologikoen (UF) multzo zabaleko bi kategoria dira (beste bat, esaterako, esaera zaharrena da). UFak liburua irakurri, ogia erosi eta antzeko “konbinazio libreetatik” bereizten dituen ezaugarria idiomatikotasuna da. Ezaugarri konplexua da, zenbait osagai edo propietatez osatua, eta graduala.
Bada, ikerkuntza-lan honen helburua izan da izena+aditza osaerako euskarazko UFak testuetatik (corpusetik) automatikoki eskuratzeko eta haien idiomatikotasunaren arabera karakterizatzeko teknikak garatzea.
Oinarrizko ideia da UFen propietateak testuak prozesatuz kuantifikatzea, eta neurketa horien eta idiomatikotasunaren artean korrelazioa dagoen egiaztatzeko esperimentuak egitea. Zein dira, ordea, idiomatikotasunaren bereizgarri diren propietate horiek?
Lehenak zerikusia du konbinazioaren osagaiak elkarrekin agertzeko duten “joerarekin”. UFetan, joera hori konbinazio libreetan baino handiagoa bide da (agerkidetza estatistikoki esanguratsua da). Bigarren propietatea semantikarekin lotuta dago; adibidez, lehen aipatutako adarra jo konbinazioaren esanahia ez da ‘adar’ + ‘jo’ esanahien batura. Bestela esanda, adarra jo ez da konposizionala. Azken propietatea konbinazioaren “finkotasunarekin” dago lotuta, edo, alderantzizko aldetik begiratuta, “malgutasunarekin”. Esaterako, adarra jo konbinazioan, adar izena ez da pluralean erabiltzen; eta aurrekoan jo zenidan adarra ez zitzaidan gustatu moduko perpaus erlatiboak ere ez ditugu egiten, ez behintzat aipatzen ari garen esanahiarekin. Hori malgutasun morfosintaktikoa da. Malgutasun lexikala da, berriz, honekin dago lotuta: zenbateraino ordezka dezakegu konbinazioaren osagai bat haren sinonimo batez? Arreta jarri konbinazioan, jarri aditzaren ordez ipini erabil dezakegu, baina gerrikoa estutu konbinazioan, gastuak murrizteaz ari bagara behintzat, ez da uhal sinonimoa erabiltzen.
Nola neurtu propietate horiek? Bakoitza behagai edo neurgai batekin erlazionatu behar da. Hauek dira teknika erabilienak:
- Agerkidetza: osagaien elkartze-neurriak Hau da teknika erabiliena, gure esperimentuen oinarri-lerrotzat hartu duguna. Gure ikertze-galdera izan da honen emaitzak gainerako propietateak neurtuz hobetu daitezkeen.
- Konposizionaltasun-maila: konbinazioaren eta haren osagaien arteko antzekotasun distribuzionala (esanahia testuinguruen bidez modelizatzen da, eta modelo horiek konparatzen; oso antzekoak badira, konbinazioa librea da).
- Malgutasun morfosintaktikoa: portaera morfosintaktikoen arteko distantzia estatistikoa (konbinazioaren portaeraren eta batez besteko erreferentzia-portaera baten artekoa).
- Malgutasun lexikala: osagaien ordezkagarritasuna (sinonimoen bidez konbinazio berriak sortu, eta konbinazio guztien agerkidetza-datuak konparatzea).
Bi karakterizazio-ataza bereizi dira: ranking-ataza eta sailkatze-ataza. Lehenari propietate bakun bakoitza neurtuz ekin diogu. Sailkatze-atazan, ikasketa automatikoa erabili dugu, esperimentu bakunen emaitzak konbinatuz.
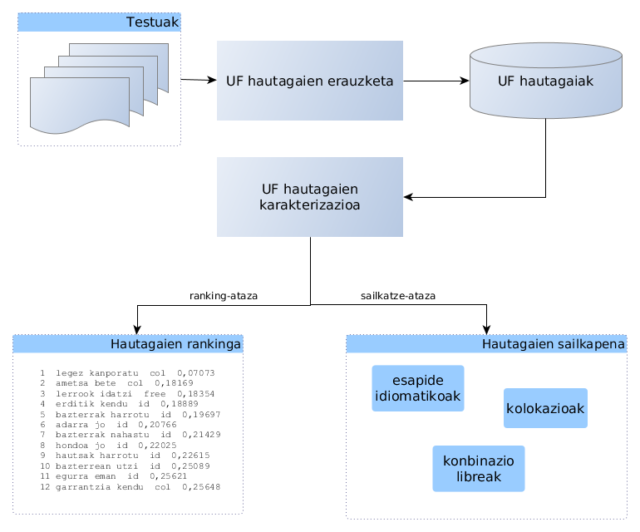
UF hautagaiak testutik automatikoki erauzteko eta forma kanonikoa esleitzeko prozesu automatikoa garatu da. 74 milioi hitzeko kazetaritza-corpus bat prozesatu dugu. Ebaluaziorako gold standardtzat, aditu-talde batek eskuz sailkatutako 1 200 hautagaiko multzo bat erabili dugu, hiru kategoriatan banatua: esapide idiomatikoak (lokuzioak), kolokazioak eta konbinazio libreak.
Neurketaren emaitzak
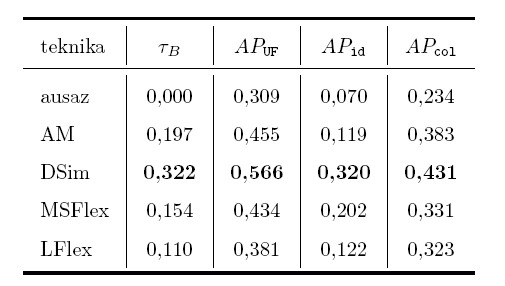
Lan esperimentalaren ondorio nagusia da arlo honetan estandar diren agerkidetza-tekniken emaitzak modu esanguratsuan gainditu direla, batez ere teknika semantikoen bidez, baina baita malgutasun morfosintaktikoaren neurketaren bidez. Aldiz, malgutasun lexikalaren neurketak ez du espero zen mailako emaitza izan.
Bestetik, fraseologiaren aurresan batzuen ebidentzia esperimentalak lortu ditugu:
a) idiomatikotasunaren konplexutasuna;
b) konposizionaltasunaren UF-kategorien zeharreko graduazioa;
c) kolokazioen erdikonposizionaltasuna eta malgutasun morfosintaktiko handia;
d) aditzak konbinazioaren idiomatikotasunarekiko duen korrelazioa.
Ikerketa honen ondorioak eta ekarpenak baliagarriak dira etorkizuneko hiztegigintzak automatizaziorantz izango duen bilakabidean eta Hizkuntza Prozesamenduaren arloko hainbat atazatan, hala nola datu-base lexikalen elikatzean, corpusen etiketatzean eta, testuinguru eleaniztunean aplikatuta, itzulpen automatikoan.
Artikuluaren fitxa
- Aldizkaria: Ekaia
- Zenbakia: 2016. urteko ale berezia, “2013-2014 Euskal Tesien 10 pasarte”
- Artikuluaren izena: Idiomatikotasunaren karakterizazio automatikoa: izena+aditza konbinazioak.
- Laburpena: Ikerkuntza-lan honen helburua izan da izena+aditza osaerako unitate fraseologikoak (UFak) corpusetik automatikoki eskuratzeko eta haien idiomatikotasunaren arabera karakterizatzeko teknikak garatzea eta esperimentalki testatzea. Idiomatikotasuna UFen ezaugarri definitzailetzat hartu dugu, eta haren lau propietate hauek hartu ditugu neurgai gisa: instituzionalizazioa (idiosinkrasia estatistikoa), ez-konposizionaltasun semantikoa, finkapen morfosintaktikoa eta finkapen lexikala. Ondorio nagusia da arlo honetan estandar diren agerkidetza-tekniken emaitzak modu esanguratsuan gainditu direla, batez ere teknika semantikoen bidez, baina baita malgutasun morfosintaktikoaren neurketen bidez ere. Aldiz, malgutasun lexikalaren neurketek ez dute espero izatekoa zen mailako emaitza izan. Azkenik, teoria fraseologikoaren aurresan batzuen ebidentzia esperimentalak lortu ditugu.
- Egileak: Antton Gurrutxaga, Iñaki Alegria eta Xabier Artola
- Argitaletxea: UPV/EHUko argitalpen zerbitzua.
- ISSN: 0214-9001
- Orrialdeak: 47-68
- DOI: 10.1387/ekaia.14544
Egileez: Antton Gurrutxaga Elhuyar Fundazioko Hizkuntza eta Teknologia unitateko ikertzailea da. Iñaki Alegria eta Xabier Artola UPV/EHUko Donostiako Informatika Fakultateko Lengoaia eta Sistema Informatikoak saileko irakasleak dira, eta Ixa taldeko ikertzaileak.
—————————————————–
Ekaia aldizkariarekin lankidetzan egindako atala.
