Giza genomaren entziklopedia
Jose Ramon Bilbao
Homo sapiens espeziearen genomaren sekuentziazioak agerian utzi zuen oso urriak zirela gene proteina-kodeatzaileak eta horrek harridura eragin zuen zientzialarien artean, nolabait ezbaian jarri zelako genoma hitzaren jatorrizko esanahia, hau da, “gene guztien multzoa”.
Izan ere, ordura arteko espekulazioek 100.000tik gora gene egongo zirela aurreikusten zuten, 23 kromosomatan banatutako 3.000 milioi DNA-nukleotidoetan zehar. Hasierako analisiek, ordea, 35.000 baino ez zuten aurkitu eta egun, ikertzaileek 20.000 gene ingurura murriztu dute kopuru hori. Beraz, genomaren %2a baino ez dagokie proteinak ekoizteko geneei. Orain arte uste izan da genomako gainontzeko DNA eboluzioaren historian zehar pilatutako zaborra edo txatarra besterik ez zela, funtziorik gabeko basamortu genomikoa. Bazegoen hori pentsatzeko arrazoi nagusi bat: bakterioetan, bizidunen eskalaren beheko aldean daudelarik ere, kodetze-eremuak genomaren %80tik gora betetzen du, eta beraz, genoma ez kodetzailea ez da bizitzarako ezinbestekoa. Hala ere, asko izan dira azalpen errazegi hori zalantzan jarri dutenak eta zientzialariek sumatzen zuten genomaren azterketa funtzional sakona egin behar zela.
2003an bertan, giza genomaren sekuentziazioa plazaratu berria zela, EEBBetako National Human Genome Research Institute izenekoak (NHGRI) sekuentzia funtzionalen katalogazioari eta funtziorik gabeko basamortuaren auzia argitzeari ekin zion, Encyclopedia Of DNA Elements (ENCODE) egitasmoa bultzatuz. Hasierako proiektu pilotuak genomaren 44 eremu (30 milioi base, edo genomaren %1) sakon aztertzea hartu zuen helburu. Emaitzek erakutsi zuten kokapen horietako DNA gehiena nonbait aktiboa dela, eta horrela, genomaren ikuspegi gene-zentrista kolokan jarri zuten, ikertzaileek aurkitu baitzuten RNA ekoizteko aktibitate nabarmena zegoela proteina-geneen mugetatik at. Orain zehaztu behar zuten aztertutako zati txiki horren parekoa ote zen artean arakatu gabe zegoen genomaren gainontzeko %99a. Horretarako, genoma osoko nukleotido bakoitzak zer egiten duen argitzea beste aukerarik ez zuten.
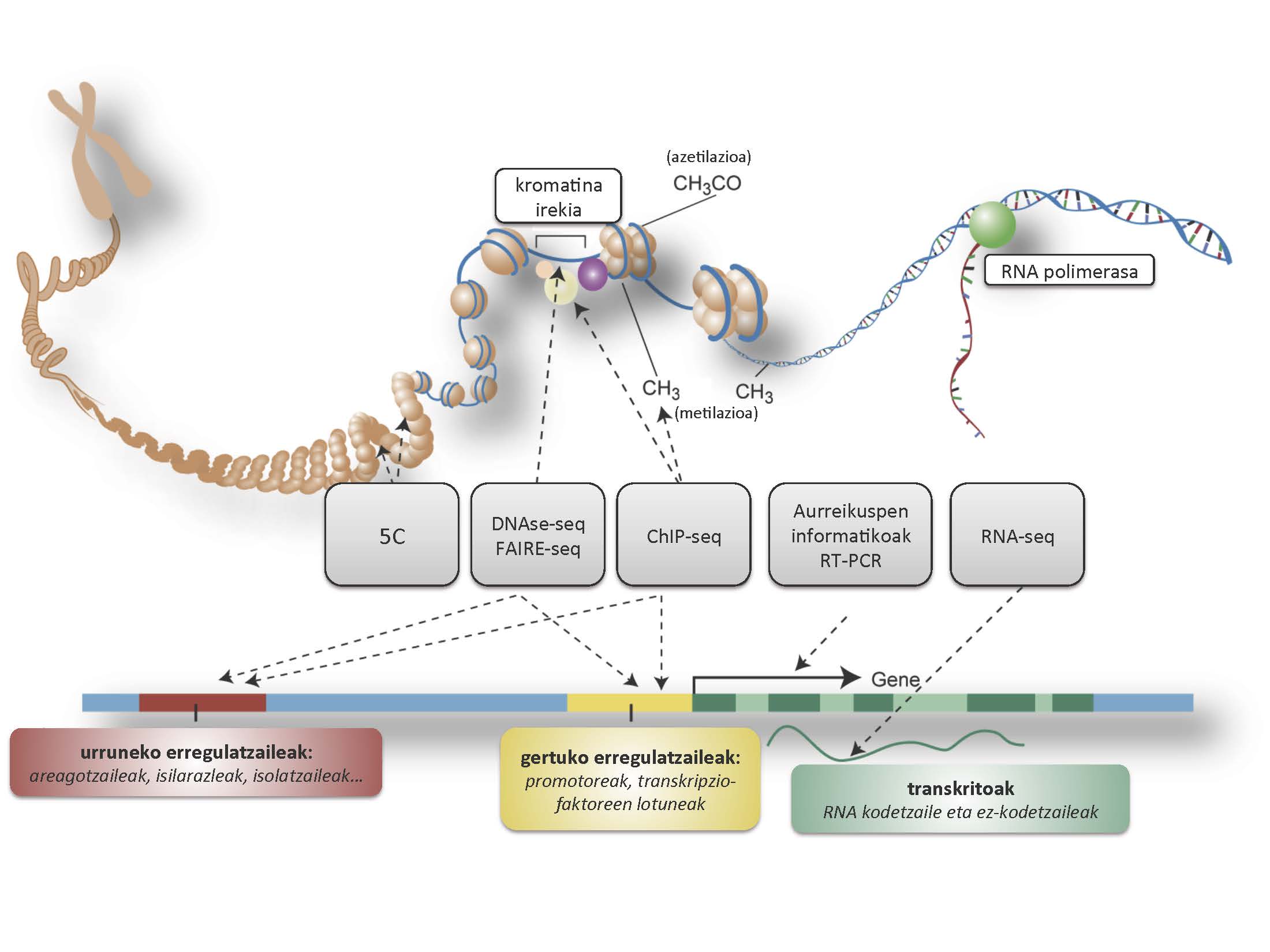
Egitasmo erraldoi horretarako, munduko 32 ikerketa-taldek ehunaka esperimentu egin zituzten hamar urtean (1. irudia). Zelula mota desberdinek eremu genomiko espezifikoak erabiltzeko aukera dutela kontuan hartuta, sei zelula-lerro desberdinen genomak arakatu zituzten goitik behera: GM12878 odoleko globulu zuri heldugabea, K562 leuzemiatik eratorritako zelula-lerroa, H1-hESC zelula ama enbrionarioa, gibeleko minbizitik eratorritako HepG2 lerroa, HeLa zelula-lerrorik erabilienetakoa eta giza zilborrestearen ehuna. Horietaz gain, analisi azalezkoagoak egin zituzten beste 140 zelula motatan eta beste hainbat ehunetan. ENCODE egitasmoko proiektuko ikertzaileek RNAren sekuentziazioa (RNA-seq) erabili zuten transkribatzen diren DNA nukleotidoak identifikatzeko; ondoren RNA transkripto horiek proteinetara itzultzen diren ala ez begiratu zuten. Horrela, in vitro egiaztatu nahi zituzten algoritmo informatikoek genomaren sekuentzian aurreikusitako gene proteina-kodetzaileak, eta gene horien hasiera, bukaera eta kodetze-eremuak zehaztu. Goian aurreratu bezala, ikusi da gure genoman mota horretako geneen kopurua ez dela 20.000tik gorakoa. Beste gutxi gorabehera 11.000 DNA-zati, eboluzioan zehar pilatutako mutazioek isilarazitako “gene hil” edo pseudogenetzat hartu izan dira; hala ere, ikusi da zenbait zelula motetan aktibo daudela (2. irudia). Dena den, ENCODE egitasmoaren ekarpen berritzaileena, zalantzarik gabe, amaiera-produktu gisa RNA duten gene ugarien identifikazioa izan da. Proiektu pilotuak aurreratutakoa berretsiz, ENCODE egitasmoak egiaztatu du genoma osoko sekuentzien %76 transkribatzen direla, gutxienez 8.800 RNA molekula txiki eta 9.600 RNA luze ez kodetzaile ekoizteko.
RNA molekula horiek hainbat funtzio betetzen dituzte hainbat esparrutan: besteak beste, zelulan, kromosomen osagarri den kromatinaren konformazioan, geneak piztu eta itzaltzeko funtsezkoak diren transkripzio-faktoreen aktibazio eta garraioan eta RNA mezulariaren proteinarako itzulpenaren kontrolean. Izan ere, frogatua dago erregulazio genomikoan osagai garrantzitsuak direla, eragiteko mekanismoak oraindik ezezagunak bazaizkigu ere.
Transkripzioaz harago, DNAren nukleotidoen eta transkripzio-faktoreen moduko proteinen arteko elkarrekintzak ere aztertu dira ENCODE egitasmoan. Orokorrean, zelula mota bakoitzean 300.000 dira proteina desberdinekin lotuta aurkitu zituzten eskualde genomikoak eta, aztertutako zelula mota guztiak batera hartuta, 4 milioi lotune identifikatu dira genoman. Gutxi gorabehera genomaren %42 proteinak lotzeko itu-sekuentzia espezifikoak dira. Eremu horietan, ezezagunak diren kinadei erantzunez, kromatinak trinkotasuna galdu egiten du eta DNA-sekuentzia agerian geratzen da, proteinarentzat eskuragarri. Hainbat itutan, sekuentziazio teknika bereziak erabiliz, loturan zuzen parte hartzen duten nukleotido jakin batzuk identifikatu dira. Zenbait kasutan, gainera, lotuneko nukleotido gako horiek bat datoz gaixotasun konplexuak pairatzeko arrisku genetikoa areagotzen duten posizio polimorfiko edo SNPekin (ingelesez, Single Nucleotide Polymorphism). Diabetea, minbizia, Crohn gaitza edo obesitatea bezalako gaixotasunekin lotuta dauden aldaera genomiko horietako %12ek transkripzio-faktoreen itu-sekuentziak aldatzen dituzte eta %30etik gora kromatina eztrinkoko eremu aktiboetan daude. Horrek guztiak bide berriak zabaldu ditu erregulazio genomikoaren eta gaixotasun konplexuen arteko harremanak aztertzeko, ikusi baita orain arte aztertutako proteina-kodetzaileetako mutazioek oso eragin txikia dutela gaixotasun horietan.
Kromatinaren konformazioaren eta transkripzio-aktibitatearen markatzaile epigenetikoak ere arakatu dira. DNA-sekuentzia aldatzen ez duten markatzaile horien artean ditugu DNAren zitosinen metilazioa eta histonen aldaketa kimikoak (metilazioak eta azetilazioak). Aldaketa epigenetiko horien arabera, definituta daude eremu genomiko funtzional desberdinak bereizten dituzten kromatina egoerak, hala nola transkripzioaren areagotzaileak, isilarazleak, errepresoreak eta isolatzaileak (3. irudia). Kromatinaren immunoprezipitazioa eta sekuentziazioa elkartzen dituen ChIP-seq teknikan proteina jakin baten aurkako antigorputza erabiltzen da hari lotutako zatiki genomikoak erauzteko; ondoren, sekuentziazio bidez identifika daitezke lotura-eremu horien nukleotidoen sekuentzia eta kokapena. Era horretan aztertu dira ehundik gora transkripzio-faktore eta DNAri lotzen zaizkion bestelako proteina batzuk, DNArekin batera kromatina osatzen duten histonak eraldatzen dituztenak barne. Dagoeneko genomaren %8a proteina horien itua dela ikusi da, eta eremu kopurua askoz handiagoa dela aurreikus daiteke, oraindik proteina asko aztertzeke baitaude. Azkenik, 5C izeneko teknikaren bitartez, ikusi da urruneko sekuentzia genomikoak harremanetan daudela, kontaktu fisikoan. Zenbait kasutan, gainera, kromosoma desberdinetako eremuak lotuta ageri dira, batez ere geneen hasierako sekuentzietan.
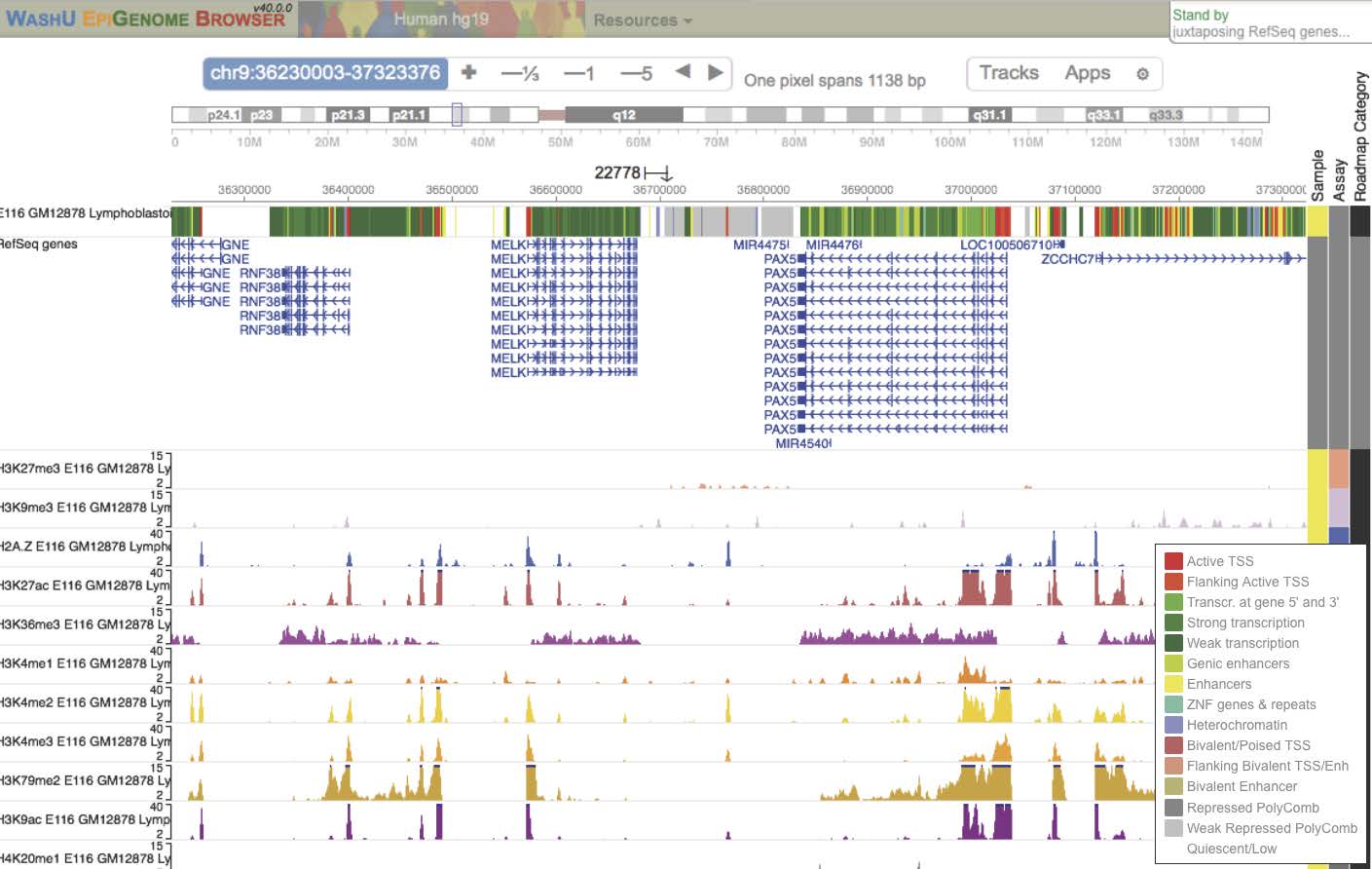
Bigarren panelean, eremu horretan identifikatuta dauden geneak. Hortik behera, esperimentuetan behatutako histonen modifikazioen maiztasuna posizio genomiko bakoitzean. Adibidez, H3K27ac marka (3. histonaren 27. posizioan dagoen lisina aminoazidoaren azetilazioa) goiko panelean gorriz adierazitako transkripzioaren hasierarekin uztartu da (PAX5 genearen hasieran ikus daiteke eremu gorri zabala).
ENCODE egitasmoak, erakutsi digu lehen uste zena baino askoz ere konplexuagoa dela geneen erregulazioa. Dimentsio anitzeko sare baten itxura duen prozesu horretan, eten gabeko elkarrekintzan daude genetik gertu zein urrun dauden DNA-sekuentzia erregulatzaileak, proteinara itzultzen ez diren RNA molekula desberdinak, DNAri lotzen zaizkion proteina espezifikoak eta DNAren beraren aldaketa kimikoak. Aktibatze eta isilarazpen koordinatuen ondorioz gertatzen dira zelulen eta ehunen espezializazioa edo zelula anitzeko bizidunen garapena, eta erregulazio-ahalmen horren galera progresiboan legoke zahartzaroarekin batera agertu ohi diren gaixotasun endekatzaileak.
Osatzen ari den entziklopediak gene eta genomari buruzko ideia berriak dakartza, eta testuliburuetan dauden kontzeptu asko berrikusi behar dira. Ikuspegi praktikotik, oso baliagarriak izango dira Biologia hobeto ulertzeko eta hainbat gaixotasun genetikoren patofisiologia argitzeko. ENCODE egitasmoak lortu duen informazio guztia publikoa da, hainbat nabigatzaile genomikotan ikusgai. Gainera, nahi duenak emaitza gordinak eskura ditzake ENCODE Project helbidean, bere hipotesiak probatzeko edo galderak erantzuteko.
Esteka interesgarriak
- ENCODE egitasmoaren atal desberdinei buruz Nature aldizkarian argitaratutako artikuluak.
- ENCODE egitasmoaren emaitza guztiak UCSC Santa Cruz nabigatzaile genomikoan ikus daitezke. Adibide honetan, GM12878 zelulen ezaugarri genomikoak ikus daitezke, baina ehunaka panel gehiago ager daitezke.
Egileaz: Jose Ramon Bilbao Biologian doktorea da, UPV/EHUko Medikuntza eta Erizaintza Fakultateko irakaslea eta BioCruceseko Zeliakiaren Ikerketa Funtzionalak ikerketa-taldearen zuzendaria.
1 iruzkina
[…] hamarkadan gauza oso interesgarriak egin dira gene-arkitekturaren konplexutasuna aztertzeko: ENCODE edo GTEx bezalako egitasmoek dena oso konplexua dela berretsi dute eta informazio kopuru erraldoia […]